

Storage Spaces Direct / S2D - Disks stuck in maintenance mode
Having a storage space direct cluster stuck in storage maintenance mode feels quite unlucky. Luckily we've fond a way to fix this!
Working on one of our S2D clusters, we've had quite a strange issue. During a regular maintenance, a colleague reported that the system had issues enabling the maintenance mode. Basically disks entered maintenance mode, but the process didn't continue.
Having waited quite a while, we decided to proceed with (regular) updates and have the affected node being restarted. So far no further issues, disks had been in maintenance mode afterwards. The only thing: We haven't been able to disable maintenance mode. Mostly like JT pedersen describes here: Azure Stack HCI PhysicalDisks won't go out of storage maintenance mode - jtpedersen.com IT made simple
The system is a test-environment running only two nodes of Windows Server 2022 with a bunch of HDD, SSD and NVMe on each node. (First installation had been Windows Server 2016, upgraded to 2019, then 2022). Technically the solution might also work on Azuer Stack HCI which is using S2D under the hood.
TL;DR - Just tell me how to fix it
In case you just want to skip the whole story, you might just try the following step, for every disk that is stuck.
# prepare args
$arguments = @{}
$arguments.Add("EnableMaintenanceMode", $false)
# select affected disk
$sfd = Get-PhysicalDisk -DeviceNumber 2000
# change mode
Invoke-CimMethod -MethodName "Maintenance" -Arguments $arguments -InputObject $sfdWhat happens here is: We're invoking the Maintenance method on the CIM Class that represents a physical disk (which internally translates/maps calls to WMI methods, if i'm right here). Calling this, does not verify higher level objects like virtual disks, it's more or less "just" changing a flag on the disk (which might be applied using regular metadata modification of the storagepool).
By running this on every disk in maintenance state we're enabling access to the disks again, which will in turn allow storagejobs to resume which will then fix our virtualdisks which will then make us happy.
The long way
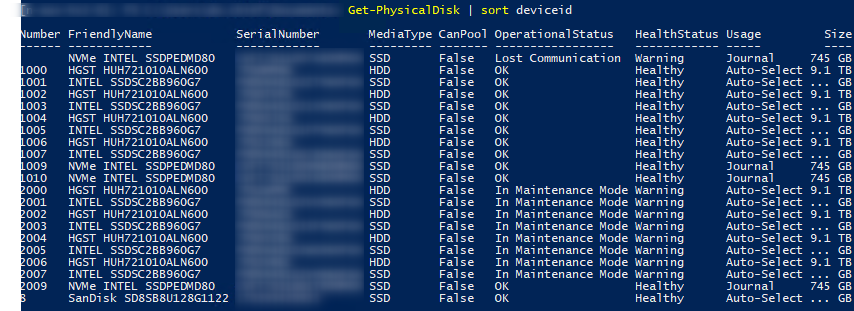
Failure state
So, our system has been stuck, just like shown above and on the text version right below.
Number FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Usage Size
------ ------------ ------------ --------- ------- ----------------- ------------ ----- ----
2000 HGST HUH721010ALN600 XXXXXXXX HDD False OK Healthy Auto-Select 9.1 TB
1004 HGST HUH721010ALN600 XXXXXXXX HDD False OK Healthy Auto-Select 9.1 TB
1002 HGST HUH721010ALN600 XXXXXXXX HDD False OK Healthy Auto-Select 9.1 TB
1005 INTEL SSDSC2BB960G7 XXXXXXXX SSD False OK Healthy Auto-Select ... GB
1007 INTEL SSDSC2BB960G7 XXXXXXXX SSD False OK Healthy Auto-Select ... GB
1009 NVMe INTEL SSDPEDMD80 XXXXXXXX SSD False OK Healthy Journal 745 GB
1006 HGST HUH721010ALN600 XXXXXXXX HDD False OK Healthy Auto-Select 9.1 TB
2009 NVMe INTEL SSDPEDMD80 XXXXXXXX SSD False OK Healthy Journal 745 GB
2005 INTEL SSDSC2BB960G7 XXXXXXXX SSD False In Maintenance Mode Warning Auto-Select ... GB
2010 NVMe INTEL SSDPEDMD80 XXXXXXXX SSD False OK Healthy Journal 745 GB
2002 HGST HUH721010ALN600 XXXXXXXX HDD False In Maintenance Mode Warning Auto-Select 9.1 TB
1010 NVMe INTEL SSDPEDMD80 XXXXXXXX SSD False OK Healthy Journal 745 GB
1001 INTEL SSDSC2BB960G7 XXXXXXXX SSD False OK Healthy Auto-Select ... GB
1003 INTEL SSDSC2BB960G7 XXXXXXXX SSD False OK Healthy Auto-Select ... GB
2004 HGST HUH721010ALN600 XXXXXXXX HDD False In Maintenance Mode Warning Auto-Select 9.1 TB
2007 INTEL SSDSC2BB960G7 XXXXXXXX SSD False In Maintenance Mode Warning Auto-Select ... GB
2006 HGST HUH721010ALN600 XXXXXXXX HDD False In Maintenance Mode Warning Auto-Select 9.1 TB
1000 HGST HUH721010ALN600 XXXXXXXX HDD False OK Healthy Auto-Select 9.1 TB
2003 INTEL SSDSC2BB960G7 XXXXXXXX SSD False In Maintenance Mode Warning Auto-Select ... GB
2001 INTEL SSDSC2BB960G7 XXXXXXXX SSD False In Maintenance Mode Warning Auto-Select ... GThat's it. No step forward, no step backward. Actually every operation trying to modify this state either returned an error or has been stuck forever (despite we didn't wait actually "forever", but a few hours :-)).
Things that did NOT work
Finding a solution for this hasn't been easy (talking about it now the solution seems rather simple). We tried to use common commands like:
- Disable-StorageMaintenanceMode
- Repair-ClusterS2D -DisableStorageMaintenancemode
- Modify S2D properties like disabling caching
- Invoke Maintenance method via CIM on MSFT_StorageHealth directly
None of this was able to change the state of the disks and returned a message similar to this:
# Call Maintenance on MSFT_StorageHealth
# - TargetObject = StorageFaultDomain (like Enclosure or PhysicalDisk)
# - EnableMaintenanceMode = false
# Invoke-CimMethod -MethodName "Maintenance" -Arguments $arguments -InputObject $sh
Invoke-CimMethod : Currently unsafe to perform the operation
Extended information:
One or more virtual disks are not healthy.
Virtual Disks:
FFB25D72D923784E89375D69D57D8202
Recommended Actions:
- Repair associated virtual disks that have lost their redundancy.
- To continue with the operation do not use the 'VirtualDisksHealthy' flag.
The associated virtual disks may be at a greater risk of becoming unavailable.
Activity ID: {58feeddf-67b0-4ec1-92d1-cdeddacac896}
In Zeile:1 Zeichen:1
+ Invoke-CimMethod -MethodName "Maintenance" -Arguments $arguments -Inp ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (StorageWMI:) [Invoke-CimMethod], CimException
+ FullyQualifiedErrorId : StorageWMI 9,Microsoft.Management.Infrastructure.CimCmdlets.InvokeCimMethodCommandSo, we can assume that the endpoint has an option to omit VD check (our VDs are in degraded state, which is expected - but maybe this has an issue here).
In our setup, we are very confident that we don't have an issue about our VDs, they are running on a single copy very fine, we just cannot disable maintenancemode and let the storagejobs resume.
Well, so - passing a ValidationFlags argument with a value of 0 (= uint16, no flags set) returns a successful status code on invocation, but doesn't actually change the disks state. As I've not been able to find any documentation about valid flags, this path ended here. Nearly.
One thing that did work
Digging around quite a while lead me to one method: Maintenance via MSFT_PhysicalDisk.
So, there's a method available on these objects. Let's check it's arguments:
Name CimType Qualifiers ReferenceClassName
---- ------- ---------- ------------------
EnableIndication Boolean {ID, In}
EnableMaintenanceMode Boolean {ID, In}
IgnoreDetachedVirtualDisks Boolean {ID, In}
Timeout UInt32 {ID, In}
ValidateMaintenanceMode Boolean {ID, In}
ExtendedStatus Instance {EmbeddedInstance, ID, Out}Quite interesting, there's also an option to disable maintenance mode, so let's invoke it.
$sfd = Get-PhysicalDisk -DeviceNumber 2000
$arguments = @{}
$arguments.Add("EnableMaintenanceMode", $false)
Invoke-CimMethod -MethodName "Maintenance" -Arguments $arguments -InputObject $sfdAnd - yes - finally. Maintenance mode is disabled on this disk. Repeat this step on every disk and storagejobs will resume.
While having jobs running, let's check the fault domains:
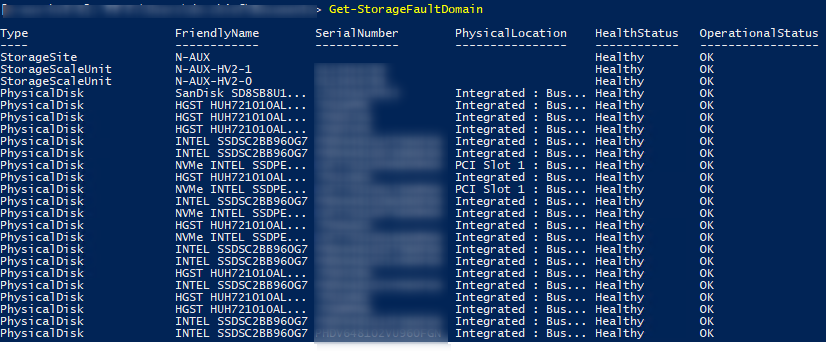
After job completion, VDs are healthy again.

Watching the solution this sounds rather simple: just fetch the CIMClass definition for the type of affected device, check methods and invoke one of them. Doesn't seem like searching for a solution for hours :-)




