

Performance issue with hyper-threading
On some of our setups we had an issue with VM to VM latencies (no the same host) ranging between 1000-2000ms. This article will describe the issue and how we solved it.
On one of our customer's setups we had a really weird performance issue which i will talk about in this post. All startet that an application this customer uses on many sites has been running painful slow on this (newer) site. Beginning from application startup to using it has felt like running through a tarpit. All application servers are running as virtual machines on top of a hyper-v based hypervisor (running Microsoft Windows Server 2019). The relevant hardware component here is the CPU which is an Intel Xeon Gold 5128 (Cascade Lake).
We did several diagnostics, especially on the I/O subsystem - as there's a high chance that such issues relate so this. Detecting bottlenecks on CPU or memory (utilization) are rather easy. Unfortunately, we didn't have any success with this.
Pinpointing the issue
The mentioned application relies on network (due connectnig to a SQL database) - so we did basic network checks, everything seemed fine one a first glance. Troughout has reached line rate, etc. Yet - after some further investigation we noticed that latencies seemed to be a little bit high. To be exact it looked like the following:
Node to Node: < 500ms
VM to Node: < 1000ms
VM to VM (different nodes): 1000-2000ms
VM to VM (same node): 1000-2000ms
VM to VM latency on a graph looks like this:
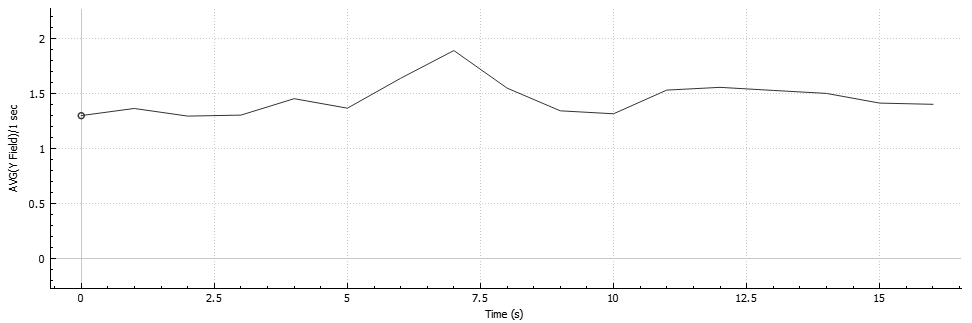
This is the point where you might get curious and ask why we're seeing such a high latency betweens VMs running on the same server. At least we did stumble upon this and got some steps further.

Searching issues on the network stack
We checked the network stacks, nic configurations, tried several adjustments like RSC, RSS, etc. The VM Switch is using SET-Teaming, so we bypass most of the network stack at all and go directly to the VMs. Yet, nothing improved anything. The only thing we noticed: Removing the antivirus reduced latency.
We're using the same scanner on many installations and are sure that it's nothing that relates to the AV engine - so no need to blame the engine here! It's just something to note: Removing the engine from the pipeline reduces latency.
Solving the issue
As things have been quite weird so far and we saw different behavior on Node to Node compared to VM to VM (same host) we came up to the idea that it might somehow relate to the hyper-v scheduler - which had changed on Windows Server 2019 (https://docs.microsoft.com/en-us/windows-server/virtualization/hyper-v/manage/manage-hyper-v-scheduler-types).
Mostly the differences in these schedulers relies on placement of threads onto physical cores - there's quite some relation to hyper-threading here. If HT is on, the scheduler will behave differently.
So our first goal was to disable hyper-threading at all to see if we might be on the tright track at all. And yes - it seems that we've been on the right track.
By solely disabling hyper-threading we shaved down VM to VM latency to 200-400ms - an improvement of 300-500%.
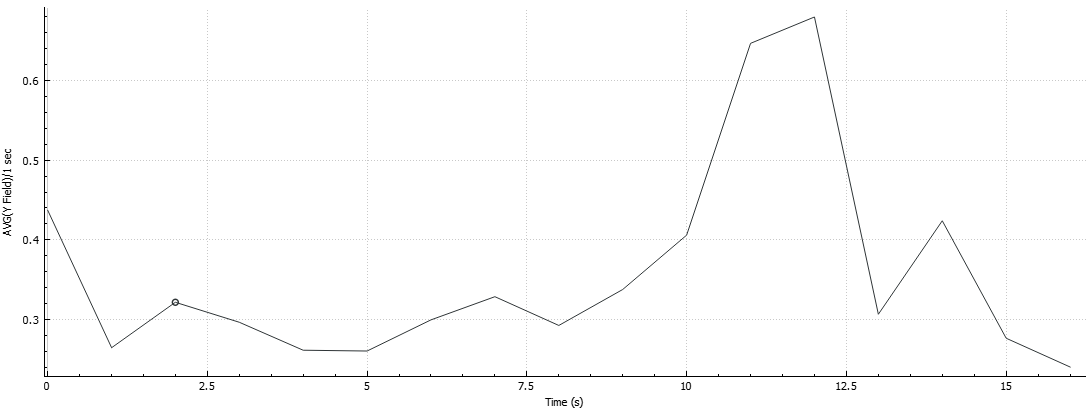
Having gained this improvement, we reinstalled the antivirus engine - without any degredation of latency (as promised before, av is not evil).
A nice side-effect is that the workload even uses less CPU time after disabling hyper-threading.
Did really disable hyper-threading solve this?
Yes - in this special case yes. Why this finally solved the issue is an even better question we cannot anwer ourselfes until now!
We did some further investigation, manually assigned classic scheduler (SMT enabled), core scheduler and played with HwThreadCountPerCore - after all we didn't find any configuration here that resulted in the same behavior as when we solely disabled hyper-threading.
We also tested a similar configuration on a server running also a cascade lake CPU (in this case Xeon Silver 4210 (Cascade Lake)) - disabling hyper-threading resulted in a major degedration of performance (measurable, 25-35%).
Should hyper-threading be disabled in general?
No - please don't!
We're talking about a very special case here which even hasn't been fully explained yet. We've not been able to reproduce this configuration as a general advice on similar setups. This is why there's no recommendation to disable hyper-threading at all. If you're not seeing any issues, keep using it (just make sure you're using a scheduler that supports prevention of spectre/meltdown).
If you're seeing a similar issue like described above, give it a shot and disable HT for a test. You might be lucky and it might be solve your issues - this is why i'm posting this.
If you've any idea and are able to tell why disabling HT solved our issue, feel free and get in touch with me - i'm more than curious to understand what's behind the scenes here.
Until then - stay tuned.






{kind=link}