

Exchange database fails with serious I/O error
Running exchange servers there's a slight chance that the database growth results in a state where the filesystem cannot allocate anymore segments. Let's fix this.
Over the last months we saw one specific, critical error multiple times on Microsoft Exchange Server installations. To be correct this issue affected Exchange Server 2016 installations, but will probably also affect Exchange Server 2019 - just not yet.
Here's an example error message that occurs in such a scenario
Information Store - Mailbox Database 2115052603 (5784) Mailbox Database 2115052603: Fehler nach 0.000 Sekunden beim Schreiben in Datei "C:\Program Files\Microsoft\Exchange Server\V15\Mailbox\Mailbox Database 2115052603\Mailbox Database 2115052603.edb" bei Offset 355542761472 (0x00000052c8000000) für 0 (0x00000000) Bytes mit Systemfehler 665 (0x00000299): "Der angeforderte Vorgang konnte aufgrund einer Dateisystemeinschränkung nicht abgeschlossen werden. ". Fehler -1022 (0xfffffc02) bei Schreiboperation. Wenn dieser Zustand andauert, ist die Datei möglicherweise beschädigt und muss aus einer vorherigen Sicherung wiederhergestellt werden.Trying to repair the database using ESEUTIL fails
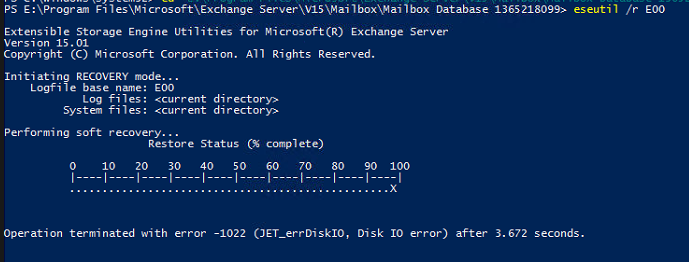
Depending on how many copies this database has, you might starting get worried at this point - especially if all copies are of the same age.
What happend?
The reason is described quite well here: Microsoft Exchange database and NTFS Fragmentation (Database error Disk IO error, Exchange Event id 482, 206, 1159, 1160 , 739) (msexchangeworld.com) Â and here The Four Stages of NTFS File Growth | Microsoft Docs
So, we need to understand how Exchange stores it's data: Exchange database files are essentially database files managed using ESENT, Microsofts Storage Engine used in many other systems like Windows Update, Failover-Cluster (S2D) Timeseries database, etc. It's a database engine that comes with Windows operating system.
As every database it has to handle growing databases. So, you get a new mail, the mail has to be stored. This is done by extending the database file and storing the data in the newly allocated space. This is quite simple so far. (Obviously there's much more with transactional logging and so on - but that doesn't matter here, so i will skip it).
The way a filesystem works is: You request a file, maybe of a given size and it will provide it to you. The space is allocated. In a perfect world it's even allocated in one piece. But what happens if you need to extend the file size? The filesystem can try to just give you free space that is attached at the end of your current location - in reality this won't happen very often. This results in file system fragmentation and is a common thing filesystems need to handle - and they do quite well.
But: How does the filesystem keep track of all the pieces? Like some sort of register where it tracks at which location on the physical disk which part of the files resides.
Attribute list size
So, NTFS needs to track all pieces and relevant metadata of a file somehow - this is done in the attribute list.
The very important part is that the size of the attribute list is limited to 256KB - that's it. No discussion.
The neat point is what happens if you increase a specific file over and over in very small increments like on a NTFS filesystem with cluster size of 4KB or 8KB. On every small increment, the attribute list also grows. Until that point where no data cannot be inserted into this list anymore.
That means: You may have plenty of free space and write and read happily. But you cannot grow this specific file anymore.
You can show the allocation using eseutil /ms
Extensible Storage Engine Utilities for Microsoft(R) Exchange Server
Version 15.00
Copyright (C) Microsoft Corporation. All Rights Reserved.
Initiating FILE DUMP mode...
File Information:
File Name: Mailbox Database 2115052603.edb
Volume Name: C:\
File System: NTFS
Cluster Size: 4096 bytes
Attribute List Size: 256 KB
Extents Enumerated: 1443802
Logical Size: 0x52c1110000 bytes (347096128 kB)
On-disk Size: 0x52c1110000 bytes (347096128 kB)
Space Saved: 0x00000000 bytes (0 kB) ( 0 %)
Database: Mailbox Database 2115052603.edb
Operation terminated with error -550 (JET_errDatabaseDirtyShutdown, Database was
not shutdown cleanly. Recovery must first be run to properly complete database
operations for the previous shutdown.) after 1.94 seconds.As you can see, the attribute list size states a size of 256 KB. As a matter of fact you can also see that the actual file size is just around 331GB (using NTFS with 4K sectors would still allow to allocated files with a size of 16TB)
The solutions
Depending on your setup, there are two ways you can go now.
Having multiple database copies
If you have a multi node setup and are replicating the database, you're a lucky fellow. Go ahead here.
Easiest way is to rebuild the database by seeding it from another node. In case your database copies are of nearly the same age you should hurry, as all replicas might have grown identically.
Having only a single database copy
Having only one copy of the database available, you need to do some more steps. Still, solving this issue is possible, it just requires some time and at least as much free disk space as the size of the affected file.
Dismount database
In case you didn't already: Dismount the affected database.
Copy the file
Yes - you will need to start by copying the database file (to be honest, moving would also work - but let's be serious. Just copy it).
This will result in a new file that has a nearly empty attribute list.
Extensible Storage Engine Utilities for Microsoft(R) Exchange Server
Version 15.00
Copyright (C) Microsoft Corporation. All Rights Reserved.
Initiating FILE DUMP mode...
File Information:
File Name: Mailbox Database 2115052603.edb
Volume Name: edb
File System: NTFS
Cluster Size: 65536 bytes
Attribute List Size: N/A
Extents Enumerated: 1
Logical Size: 0x52c1110000 bytes (347096128 kB)
On-disk Size: 0x52c1110000 bytes (347096128 kB)
Space Saved: 0x00000000 bytes (0 kB) ( 0 %)
Database: Mailbox Database 2115052603.edb
Operation terminated with error -550 (JET_errDatabaseDirtyShutdown, Database was not shutdown cleanly. Recovery must first be run to properly complete database
operations for the previous shutdown.) after 0.125 seconds.You can easily see that we attribute list is even empty. Yay.
Repair the database
There is a very high chance that the file size has been reached in the middle of a transaction (ESENT). This means that the database file is corrupt in some way, at least affecting the last transaction.
- Try a soft recovery using eseutil /r
This is the recommended first step, even it's likely to fail - Try a hard recovery using eseutil /p
If a soft recovery fails, you need to accept that you might have lost a small part of your data (if the transaction files cannot be replayed). Affected data will be the last transaction(s) before the error occurred, so you'll know at least what data is to be considered.
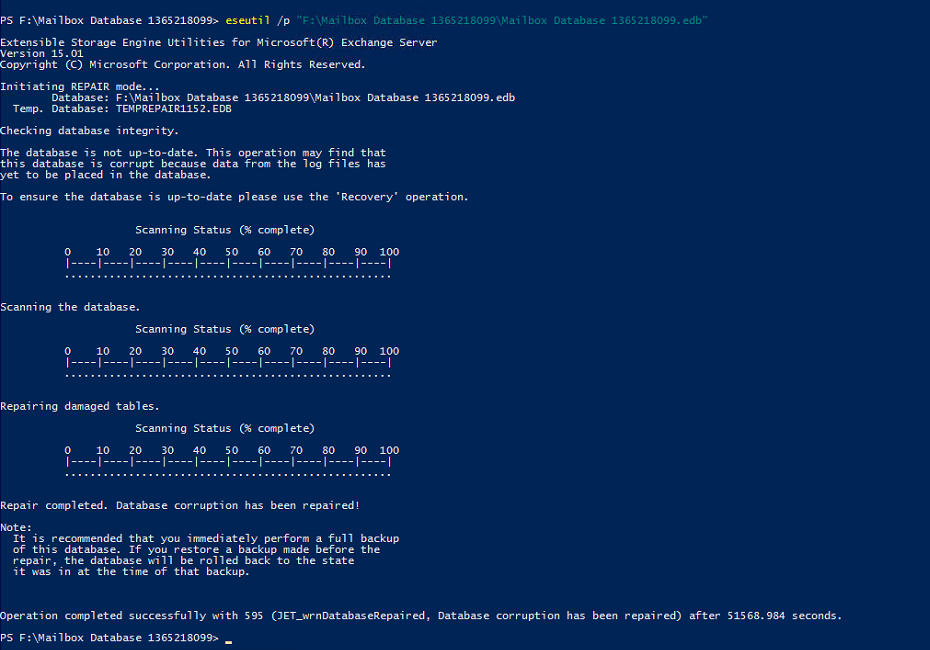
Reconfigure database
Configure exchange database to point to the location of the copied and repaired database. You might also swap directories of your copies.
Mount database
Finally, mount the database again and check if exchange shows any remaining issues.
How to prevent this?
Avoiding this is actually possible in multiple ways:
- Microsoft recommends to use ReFS to exchange databases (NOT the operating system itself). I'm not aware of such an issue on ReFS (which might be related to the next point)
- Use larger sector sizes. There's no point in using 4KB or 8KB sectors for exchange databases. Microsoft best practice: use 64KB sectors. Allocating larger sectors reduces the amount of allocations, therefore the amount of fragments.
It's quite interesting this issue occurs with ESENT. I'm not completely sure about why ESENT would increment in such small sizes, maybe it's even related to some other metadata operation. After all it shows that following best practices will provide a setup that will at least might hit this issue also, just after a runtime that's far beyond the lifetime of an exchange server installation.




