

Creating and mounting filesystems using cephfs
Having a ceph cluster cluster up and running you may want to add a filesystem that can be accessed by multiple nodes at the same time (distributed filesystem). This is where cephfs kicks in. Steps required to setup a cephfs and mount it on clients are described in this article.
Having a ceph cluster cluster up and running you may want to add a filesystem that can be accessed by multiple nodes at the same time (distributed filesystem). This is where cephfs kicks in. Steps required to setup a cephfs and mount it on clients are described in this article.
Before we're going to create a new cephfs filesystem, it's good to understand how a cephfs works actually. Here's an excerpt from the ceph docs that describes how the filesystem works:
The Ceph File System, or CephFS, is a POSIX-compliant file system built on top of Ceph’s distributed object store, RADOS. CephFS endeavors to provide a state-of-the-art, multi-use, highly available, and performant file store for a variety of applications, including traditional use-cases like shared home directories, HPC scratch space, and distributed workflow shared storage.
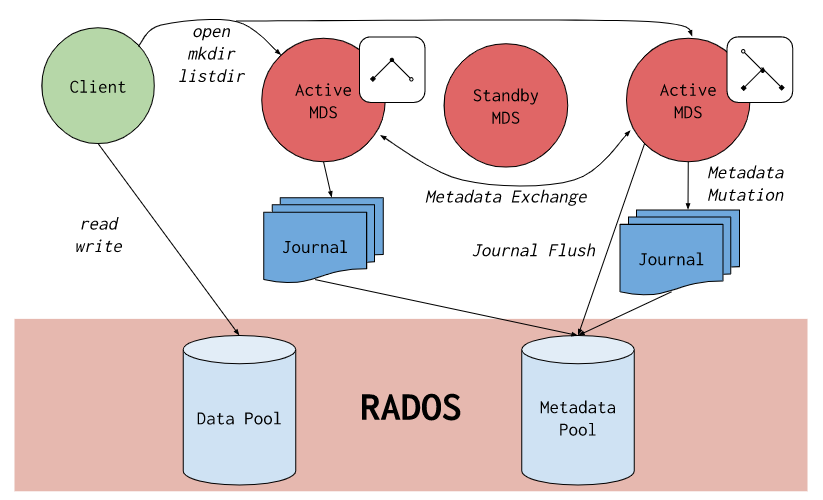
CephFS achieves these goals through the use of some novel architectural choices. Notably, file metadata is stored in a separate RADOS pool from file data and served via a resizable cluster of Metadata Servers, or MDS, which may scale to support higher throughput metadata workloads. Clients of the file system have direct access to RADOS for reading and writing file data blocks. For this reason, workloads may linearly scale with the size of the underlying RADOS object store; that is, there is no gateway or broker mediating data I/O for clients.
Access to data is coordinated through the cluster of MDS which serve as authorities for the state of the distributed metadata cache cooperatively maintained by clients and MDS. Mutations to metadata are aggregated by each MDS into a series of efficient writes to a journal on RADOS; no metadata state is stored locally by the MDS. This model allows for coherent and rapid collaboration between clients within the context of a POSIX file system.
CephFS is the subject of numerous academic papers for its novel designs and contributions to file system research. It is the oldest storage interface in Ceph and was once the primary use-case for RADOS. Now it is joined by two other storage interfaces to form a modern unified storage system: RBD (Ceph Block Devices) and RGW (Ceph Object Storage Gateway).
Read this carefully!
The magic of the filesystem relies on the decision to store the actual data on two different RADOS stores (OSD pools) - one pool for metadata and one pool for data. Metadata operations are coordinated through metadata servers (MDS) while data access is done directly to the RADOS stores (which again consist of multiple OSDs). This means that scaling is done by adding more and more stores and happens in a nearly linear fashion.
Create a cephfs
Creating a new cephfs is done quite easily using a few commands. In the example below we're creating a filesystem called cephfs0 and we're matching pools to the naming to easily identify associated resources.
# create filesystem pools
ceph osd pool create cephfs0_data
ceph osd pool create cephfs0_metadata
# create filesystem with explicit pools
ceph fs new cephfs0 cephfs0_metadata cephfs0_data
# create mds daemons
ceph orch apply mds cephfs0 3Data for this filesystem will be stored on the pools cephfs0_data and cephfs0_metadata.
After filesystem has been created three metadata servers (MDS) will be requested. Running with less is not recommended as it reduces the availability below a certain level you would expect from a highly-available filesystem.
Mounting the filesystem
To make use of the whole effort creating the filesystem it's propably your goal to mount it on some clients. Depending on your needs you should mount using kernel driver or fuse client. In general (at least for now) there is no single right or wrong here. Kernel is faster, fuse may be more up to date - so it depends.
Creating an authorization token
When you've cephfs running and want to mount it in the next step, you'll need to create an access token (if not yet in place) and use the cephfs driver to mount the filesystem.
We'll request an authorization key for the filesystem cephfs0 and client id user. Permission is readwrite (rw) on filesystem root (path = /).
ceph fs authorize cephfs0 client.user / rw | tee /etc/ceph/ceph.client.user.keyring
Mounting the filesystem to /mnt/cephfs0 using the keyring is quite easy then. If you want to mount also on additional nodes, copy the file /etc/ceph/ceph.client.user.keyring to the desired host.
Limit access to keyring
I recommend strongly to limit access to the keyring file.
chown root:root /etc/ceph/ceph.client.user.keyring
chmod 600 /etc/ceph/ceph.client.user.keyringThis will limit read access to root user only - this is fine as mounting via fstab has access to read the file but regular users don't. This prevents exposure of credentials to any users accessing the host.
Mounting the filesystem - Kernel driver
Adding a mountpoint for the filesystem is straight forward.
mkdir -p /mnt/cephfs0
mount -t ceph nuv-dc-apphost1,nuv-dc-apphost2,nuv-dc-apphost3:/ /mnt/cephfs0 -o name=user,noatime,nodiratime,_netdev
We're mounting the filesystem associated with the authorization token generated obove (clientid user) to /mnt/cephfs0. We don't provide the keyring or authorization here explicitly - the ceph driver will look at /etc/ceph/ceph.client.<clientid>.keyring and select the appropriate token automatically.
We're also pointing to three MDS nodes, that the filesystem stays accessible if even two MDS are inaccessible.
If you want to mount the same using fstab, use the following format:
nuv-dc-apphost1,nuv-dc-apphost2,nuv-dc-apphost3:/ /mnt/cephfs0 ceph name=user,noatime,nodiratime,_netdev 0 2
In both cases we're passing flags to omit setting atime for files or directories (which would cause generation of many metadata requests while we don't need to know access times).
Mounting the filesystem - FUSE client
Another way to mount a cephfs is to use the fuse client. The fuse client is running slower than the kernel driver (it's running in user mode) but is available in newer versions, because you can update it anytime - the kernel driver relies, as the name says, on the kernel and it takes some time until new builds are propagated into kernel builds. So, if you want or need to use newer releases, fuse client is the way to go.
Mounting using fuse client is available using the following command:
mount -t fuse.ceph none /mnt/cephfs0 -o ceph.id=user,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults
The same via fstab.
none /mnt/cephfs0 fuse.ceph ceph.id=user,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults 0 0
You don't need to specify MDS nodes using this driver - it will look in /etc/ceph/ceph.conf for the ceph monitor nodes and discover the parameters for the filesystem itself.
If you've no ceph.conf on the client available, you may copy it from one of your management nodes. Important settings are fsid and mon_host.
Using a newer version of ceph kernel driver (debian)
Working with debian you might have an older kernel version - this is intended by debian because the distribution is focused on stability rather than latest & greatest features.
If you want to use a newer kernel version with your debian host to get newer ceph client builds, check out this guide: https://blog.nuvotex.de/debian-update-kernel-via-backports/






{kind=link}