Choosing a postgres operator
This post describes my journey on the selection of the postgres operator that matches our demand.
One issue that kept me busy between christmas and new year has been the selection of the "best" Kubernetes postgres operator.
Why a operator?
The main desire to have an operator is to achieve two things:
- Automated major version upgrades
- Scheduled backups
I'm not sure how much you are into postgres but if you are, you are probably aware that major upgrades require some migration. The migration path can be done quickly when using links.
But... we are running on containers and our images are using one specific version. So all changes have no data migration paths in mind. Typicall upgrades start newer versions of applications and data migrations happens then internally in the application. On microservices this would be migrations from the abstraction layer or similar (like Entity Framework in dotnet or flyway in Java).
Long story short: The manual approach of doing a postgres migration cannot be mapped to a GitOps based approach, it's even more complicated than on a dedicated virtual machine.
Operator to the resuce
As a result we want to use an operator that takes all this pain away from us. It has builtin mechanisms to do all this migration steps and do these in a highly reproducible manner.
Which operator is the "best"
That's the big issue I haid.
Zalando postgres-opera
As a common recommendation I started evaluating zalandos postgres operator which is - as of today - seemingly the most widely known operator.
Typically when checking for new components I do not want to change right away again I'm carefully checking project activity on github, contributors and an overall impression of the solution. This is where the zalando operator (might be a wrong impression on my side) didn't shine, it seems that the project has recently received less maintenance than in the past. The supported postgres versions also have not been too up to date.
cloudnative-pg
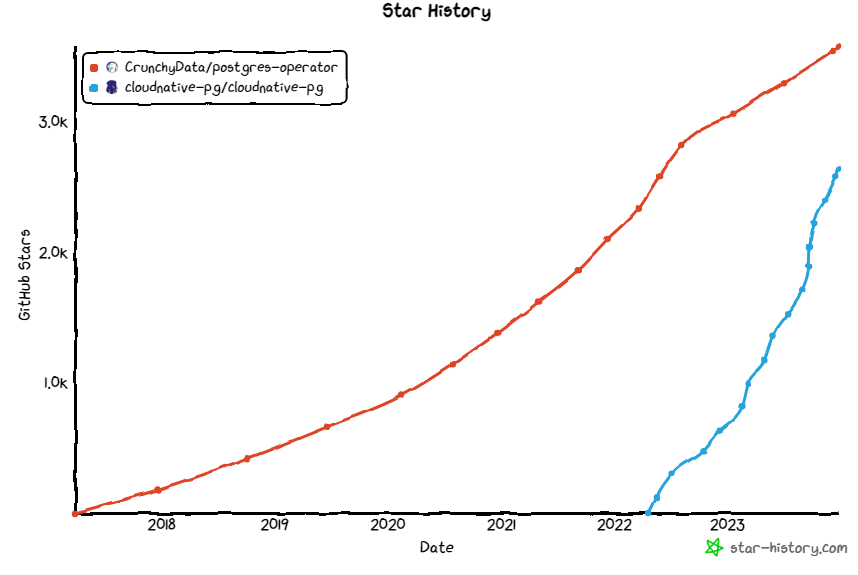
The second operator I check has been the cloudnative pg which has some awesome integrations in the postgres server and a very impressive growth on the github stars. But - it still can't do major version updates (which is a requirement) without too much manual steps. And the project seems to be still very young so that there is still too much going on compared to an established and stable solution.
CruncyData postgres-operator
So, I checked the postgres operator from CrunchyData. And so far I can say it has been (at least for our use case) the best matching operator. We can very easily define new postres clusters and the overall structure of the CRDs looks clean and stable. The objects are built with reasonable decisions in mind and allow room for further changes.
apiVersion: postgres-operator.crunchydata.com/v1beta1
kind: PostgresCluster
metadata:
name: mycluster
spec:
postgresVersion: 14
instances:
- name: instance1
replicas: 1
dataVolumeClaimSpec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 16Gi
backups:
pgbackrest:
repos:
- name: repo1
volume:
volumeClaimSpec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 8Gi
users:
- databases:
- app
name: appThis creates a cluster with a single replica for us, which is fine for our use case. To perform a major version upgrade we need to create a migration CR and annotate the cluster (for me I would also be happy if we just increment the postgresVersion in the spec and the operator trusts me that I am aware that i actually want to upgrade). It's not entirely smooth but it's okeish so to say.
Enforced wal archival
The only thing i really don't like on CrunchyData's postgres operator is the enforcement of the wal archival. I totally understand the desire to gain highest possible data resiliency - but the archival by default happens to another PV (same storage system). This means that if my storage system is dead, all copies are dead. Therefore I want to have the ability to do the backup through the storage system (like volume snapshots and in case of ceph rbd replication). This is not comparable to wal archival where I can do a point in time restore - but for us it's typically sufficent to have a consistent backup of for example a database and a blob storage (which should be from the same time, https://kubernetes.io/blog/2023/05/08/kubernetes-1-27-volume-group-snapshot-alpha/).
There are github requests for this, hopefully CrunchyData implements them and gives more control to the DevOps running the environment.
Final words
Choosing the optimal operator has been incredibly hard (for me) because there are several options but none fits all requirements for us. For now we are going with CrunchyData's solution and see how good this will work out.
But if you checkout the growth of cloudnative-pg our solution might change over time :-)